
Data is fallout, not oil

A reporter once told me he was going to write a piece about programmatic advertising called "Data is the new oil"[1]. His idea was that having data about customers and prospects is directly correlated with the ability to drive successful marketing outcomes, and thus that brands should be laser-focused on building these data assets. I argued that data isn't like oil in that once you burn a gallon of gas in your car, it's gone, whereas once you know something about a consumer, you can use it again and again. When you share it with others, it never goes away.
Since most data[1:1] is persistent, we can assume that once you share it with a company, they'll hold onto it and try to use it. There are many reasons that a data owner might want to share data with a partner, for instance, in return for money (as in a publisher selling a targeted campaign) or better outcomes (a marketer giving data to a publisher to use in targeting). However, when the data isn't intentionally shared - or when a counterparty uses the data in unintended ways - this is data leakage. Or another way of thinking about it, this is the radioactive fallout that results from the online advertising system as it works today. It's hazardous; invisible; expensive; dangerous; and nobody really wants to take the steps necessary to prevent it because it would force significant changes in life as we know it.
I believe that data leakage is at the heart of the crisis facing the open internet. Publishers undervalue their proprietary audience because the core value is leaking away from them like a balloon. Consumers install ad blockers because they don't trust the advertising ecosystem to respect their privacy[1:2]. Marketers spend money with ad networks and other intermediaries who have built "data assets"... and then hand over their proprietary data along with their money. It's a dangerous house of cards, and we need to shore up the foundations of this industry if we want the open internet to work.
In the current programmatic advertising landscape, data leakage is prevalent. To date, it has gotten little mainstream coverage for three reasons. First, it's hard to know what's leaking - and of course everyone denies that they're using data. Second, there are no standalone "anti-leaking" vendors that devote marketing dollars to publicizing the issue in the way that brand safety has been hyped up. Third, as usual, there are many vested interests that make a ton of money in the current landscape, and they have no reason to shine light on this topic. I hope to create at least a little sunlight on the issue, and perhaps we'll see some companies take this further. In part two of this article, I'll propose some steps we can take to address data leakage systematically.
My hope in writing this is to shine light on this issue. I also wrote a proposal for how the industry can address this issue.
How data leakage works
There are a few basic forms of direct data leakage where a buyer or seller might allow data out of her control, which correspond to the three basic data interactions between a buyer and a seller.
Creative Delivery
Every time an ad creative is placed on a webpage or app, it delivers a payload. This payload could be a simple GIF or a very complex set of nested HTML and Javascript. Whenever a creative makes a call to a third-party, it includes both implicit and explicit data about the user.
Here's a simple ad that I saw today on the New York Times website:
There are plenty of legitimate reasons to include third-party vendors:
Third-party counting so that the buyer can independently verify that the ad was delivered to the page (traditional third-party ad server use case)
Viewability or engagement measurement to see whether the ad appeared in the browser
Brand safety measurement to verify that the content of the page was valuable to the advertiser
Complex rendering or "rich media" logic that makes the ad more interactive
This particular creative makes 55 network calls in order to render itself:
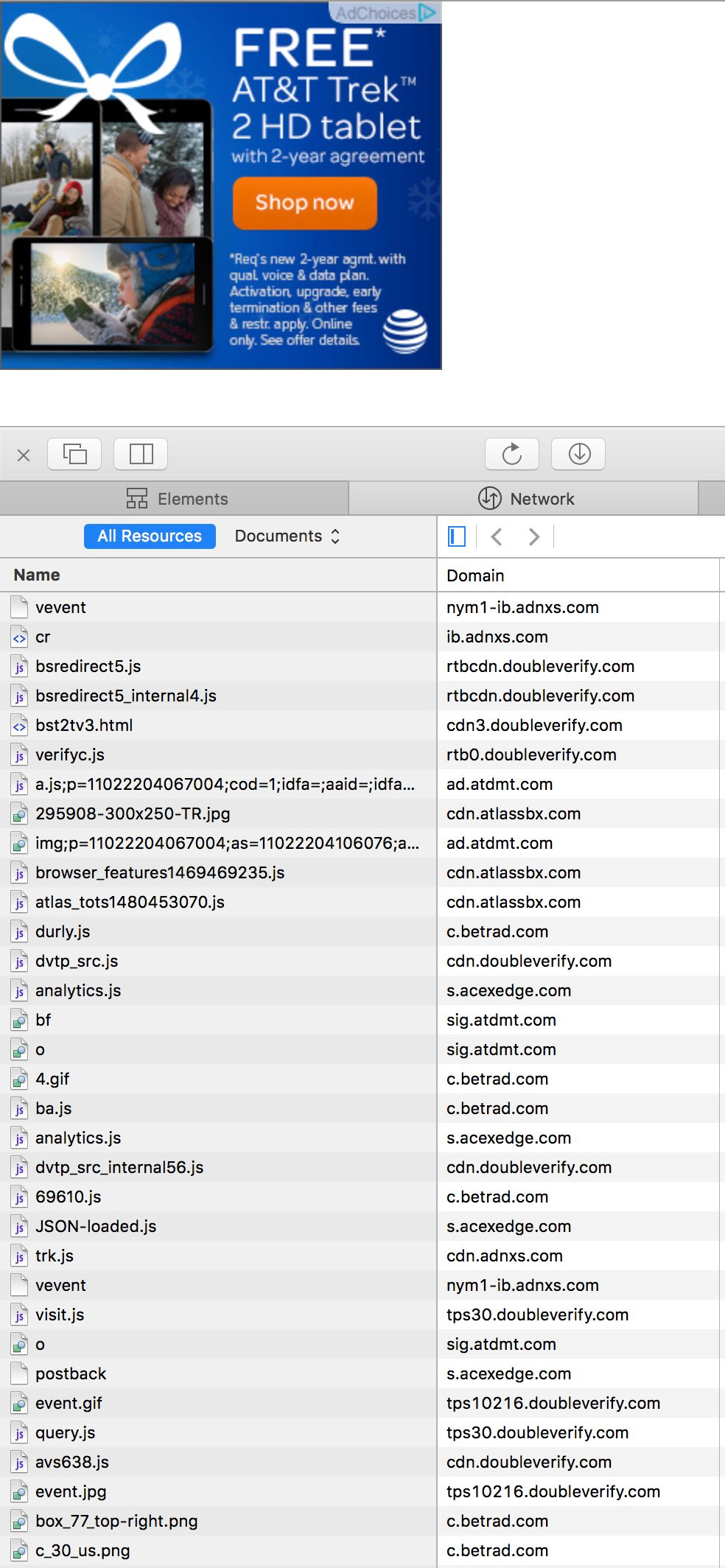
We can decode these domains and see which companies are getting called. adnxs.com is AppNexus (in this case, the DSP). doubleverify.com is Double Verify, who AT&T uses for brand safety. atdmt.com and atlassbx.com are from Atlas, which is the ad server for AT&T. betrad.com is Ghostery, which renders the AdChoices logo at the top of the ad. acexedge.com seems to be WhiteOps[1:3].
Every one of these third-party vendors gets information about the user. Here's a subset of what they can find out when the browser makes the third-party call:
The user's IP address
The user's cookie
HTTP header information (user agent, for instance)
The domain of the page and probably the full URL
The referrer (previous page loaded)
Here's the interesting one: any data that the publisher agreed to use to target the ad. How? If the insertion order says "serve this ad only to men", assuming the publisher is adhering to the deal, then we now know that this is a male user.
Adding that up, just by serving this creative, the Times has now told 5 companies that I am a male Star Wars fan that reads the New York Times. And if they're smart, these companies could learn a lot more: how I interacted with the page (in this case, I reloaded it quite a few times to try to get a good screenshot), where I was when I was on the page (probably a very strange pattern since I wrote part of this post on an airplane, part in New York, and part in Miami), what browser and OS I use, and so on.
We have no easy way to know what these 5 companies are doing with this data. We can read their privacy policies; we can negotiate contracts that explicitly lay out where and how data can be stored and used; we can look their CEOs in the eye and see if we trust them. But at the end of the day, once this data hits a persistent database, it's out of our control. To be clear, I think all of these particular companies are good actors - I especially commend Facebook for keeping the Atlas ad serving domain separate from the Facebook cookie domain - but it's easy to see the vector for data leakage here.
Note that creative delivery leakage isn't specific to programmatic; this happens whenever buyer code serves on a publisher page.
Widgets
Widgets like Disqus, Chartbeat, AddThis, and so forth are obvious vectors for data leakage, and need to attest that they do not use or share any data from the publisher. I worry about widget companies that have associated media businesses - this is the Standard Audiences product from AddThis where they package up the data they've acquired from publisher pages for resale to brands. Not to pick on them, but the AddThis home page shows logos from major publishers like Microsoft and ABC News, and then this page says "and we have their data!" How much money is this routing away from the 1300 publishers in their network? And now that AddThis is part of the Oracle Data Cloud, how is this data being resold across the digital landscape? To me, this is an explicit acknowledgement of the financial value of data leakage, and the next time I hear a publisher bemoan the impact of audience buying on their quality content, I'm going to pull up Ghostery and see how many widgets they have installed.
Programmatic Bidding
In the example above, the Times sent 5 companies some contextual information about my web browsing history. They were paid for this ad impression, and so at least there was some compensation for their data leaving their control. In addition, we can see the vendors that get access to this data.
In the world of programmatic bidding (real-time bidding, RTB, etc) most of the interactions between buyer and seller take place server-to-server, meaning that there is no direct interaction between the user's browser and the various technologies that perform the transaction. As an example, on this same page, we see that there are three header bidders installed (actually I think it's four, as Media.net is also on the page but not recognized by the Headerbid Expert plugin).
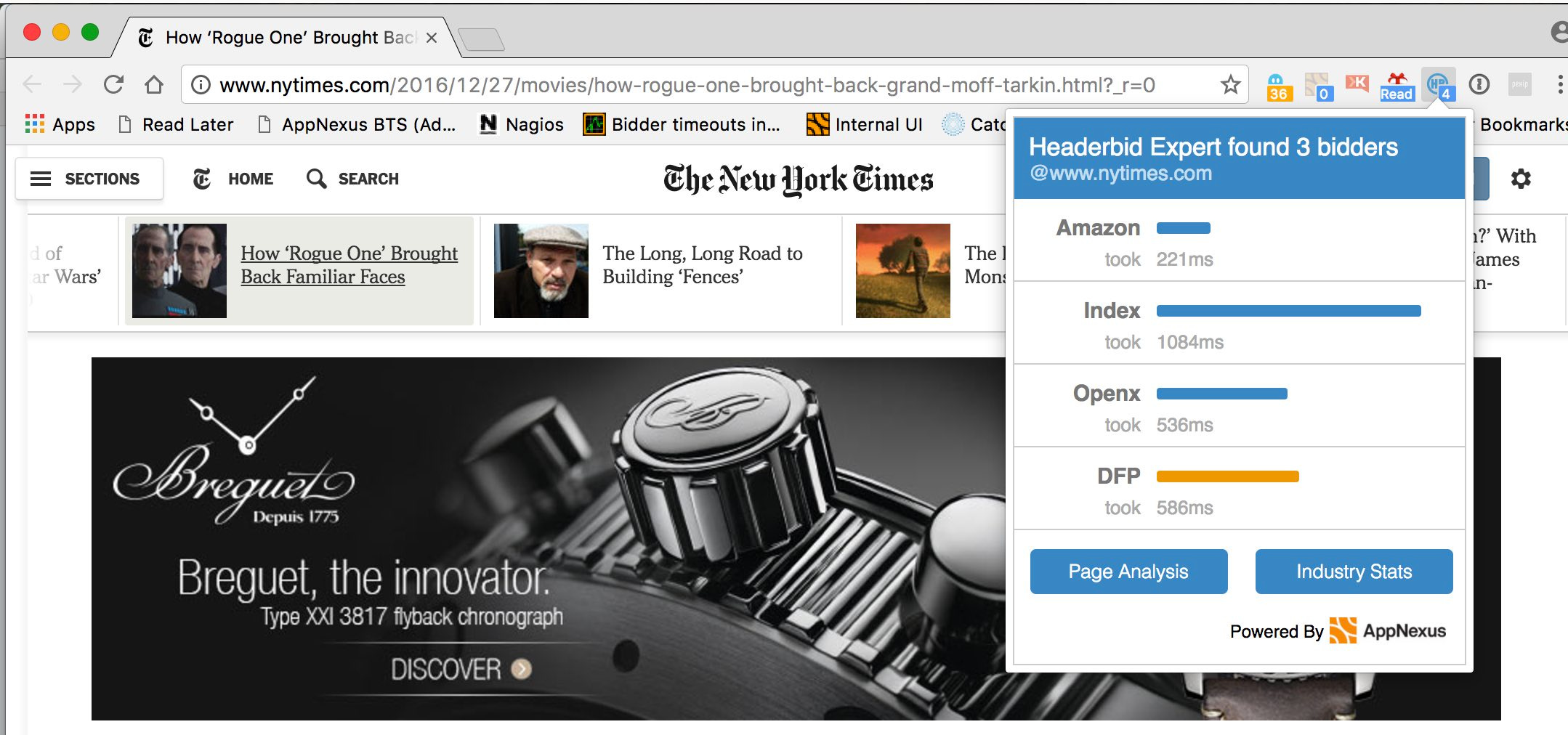
When each of these SSPs is loaded by the page, their servers make additional requests to tens or hundreds of bidders and data providers. We can't see these requests being made, because they're happening "in the cloud" so to speak, from servers to servers. Here's an example of an OpenRTB request that might be sent from this page. You can see all of the data that's getting sent, including:
The URL of the page
The referring URL (where the user came from before this)
The user's IP address
The user's browser information (user agent)
The latitude and longitude of the user
The user's cookie ID
The user's gender and year of birth
Publisher-specific user data
What's scary about this is that we have no idea who this data is being sent to. It could be good actors who are only using this data in order to decide whether to bid on this request. What's stopping the bidders from storing this data and creating behavioral profiles? How does the consumer know this is happening? Even with a browser plugin like Ghostery, you don't see the server-side requests.
Private Marketplaces
In the past few years, we have seen an explosion of "Private Marketplace" deals where buyers and sellers negotiate to have preferential access to particular inventory, often associated with particular data from the seller. For a publisher, it may seem like a no-brainer: sell the same inventory for more money to the same buyer! For the buyer, however, there is a huge benefit to having more information on the bid request.
Here's an example of how a PMP works technically in OpenRTB. A new pmp element is added to the bid request, and the seller appends each of the deal IDs that the buyer is eligible for.
Let's imagine that the New York Times has three PMPs in place with a particular agency:
Deal ID 1234 for high income users at $15.00 CPM
Deal ID 1235 for movie buffs at $7.00 CPM
Deal ID 1236 for women at $6.00 CPM
Since I'm a New York Times subscriber and I'm currently logged in, we can assume they know with reasonable confidence that I live in a relatively high income zip code in Brooklyn; that I do read movie reviews regularly, and I'm not a woman. This means that the OpenRTB request for me looks something like:
"pmp": {"private_auction": 1,
"deals": [{"id": "1234"}, {"id": "1235"}]
}
An ethical bidder would look at these deal IDs, decide if the buyer wants to buy either PMP, and pass if not. An unethical bidder, however, would simply add two data points about me to their database. They now know - permanently - that I'm a high income movie buff. Now they can go find me on other websites for much cheaper, and never compensate the New York Times for this valuable data.
One approach that might help is to obfuscate the user ID on any ad request that has deal information attached, on the thesis that it makes it hard to connect the deal data with the user ID. Another version of this would create temporary UIDs for frequency capping, or even build frequency capping into the protocol itself so the seller controls it. This would require all assets to be rendered sell-side, so that the buyer can't then pixel the user and attach a UID. This looks much more like a Facebook ads environment or walled garden, and I think is actually a potential direction that we could see the whole industry moving - but we're not there yet, and a publisher that tries this may have challenges driving demand in today's programmatic Wild West.
Put simply, any information that the publisher attaches to the bid request is vulnerable and should be considered leakage. Private marketplaces are by no means a better way to sell inventory from a data leakage perspective; in fact they are likely giving the buyer more data, with no way to know how it's being stored or used.
User ID synching
Another vector for data leakage in the programmatic world is user ID synching. The technical reason for user IDs to be synched is that every programmatic platform has a different cookie on each user. When transactions happen in the browser (as with header bidding), the browser makes a request to each bidder in its own domain, allowing the bidder to pick up its own cookie. However, to make a server-side request, the SSP and DSP must map their cookie IDs since the browser only makes a call in the SSP's domain. To do this, the SSP will constantly drop "user ID synch" pixels onto the page. For instance, to drop an AppNexus user synch pixel the SSP would call:
http://ib.adnxs.com/getuid?http://ssp.url/idsynch?uid={UID}
This makes a request in the AppNexus cookie space, so AppNexus can append its user ID in place of the {UID} macro, and then the SSP can store this. Now, in the server-side OpenRTB requests to AppNexus, the SSP will send this UID and AppNexus knows it's the same user it saw in the browser.
This makes technical sense. However, think about the data leakage implications. Every time a user synch pixel is dropped on a web page, the bidder can pick up information about the page including:
The user's cookie
IP address
Page URL
Page referrer (the previous page loaded)
Header information like User Agent
If a bidder were able to drop javascript instead of a redirect, it could get even more data from the page.
To see this happening in real life, go to a website and watch Ghostery or a similar plugin. You'll see a handful of trackers load with the page, and then you'll often see a spurt of new trackers once the page is done. This is asynchronous loading of user synch pixels. You can see it in the network traffic of the browser:
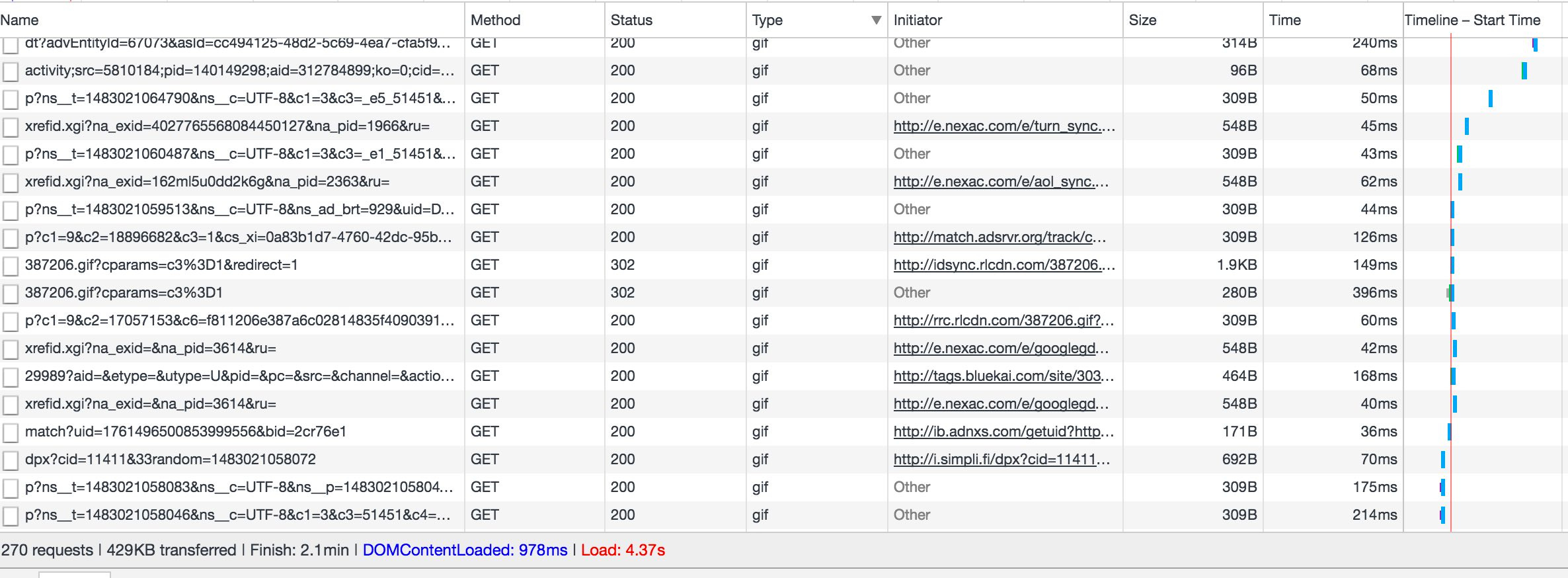
Most of those gifs are user synch calls. You can see how multiple bidders - Turn, Simplifi, The Trade Desk (adsrvr.org is their serving domain), Blue Kai / Oracle, LiveRamp / Acxiom (rlcdn.com). You can see the AppNexus getuid? call as well.
Mobile SDKs
Data leakage can happen on mobile too, of course. Here's a network trace of what one ad network collects from their mobile SDK:
{
"version": "3.12.0.0",
"adtype": "video",
"mode": 312,
"placement": 0,
"previous_session_id": "585356",
"appId": 0,
"device_info": {
"sdk_version": "3.12.1.89",
"timezone": "America\/New_York",
"make": "unknown",
"width": 1080,
"height": 1794,
"carrier": "Android",
"mcc": "310",
"mnc": "260",
"color_depth": 32,
"model": "Android SDK built for x86",
"OS": "Android OS",
"OS_version": "5.1.1",
"opt-out": false,
"androidID": "b37e686055f62bed",
"connection": "cellular",
"connectType": 5,
"disk_space": 308645888,
"heap": 214896,
"bandwith": 0,
"accelerometer": true,
"gps": true,
"gyroscope": false,
"apps": [],
"networkISO": "us",
"simISO": "us",
"carrierCountryISO": "us",
"user_agent": "Mozilla\/5.0 (Linux; Android 5.1.1; Android SDK built for x86 Build\/LMY48X) AppleWebKit\/537.36 (KHTML, like Gecko) Version\/4.0 Chrome\/39.0.0.0 Mobile Safari\/537.36",
"location_access": 3
},
"user_info": {
"age": 0,
"gender": 0,
"locale": "USA",
"lang": "eng",
"zip": "",
"income": 0,
"education": 0,
"race": 0,
"interests": [],
"misc": {},
"long": 0,
"lat": 0
},
"contextual_info": {
"cid": 0,
"pid": 0,
"cch": "585356",
"cp": "",
"cat": [],
"preferred_orientation": 0,
"adBlocks": [],
"policyId": "",
"maxAdTimeSeconds": 0,
"contentID": "",
"contentDescription": "",
"contentTitle": "",
"bundleid": "com.juteralabs.perktv",
"appversion": "4.0.1",
"returnStreamingAd": false
}
}
There's even more data available in other SDKs, especially on Android, where you can discover what apps a user has installed and more.
Conclusion
As we have seen, there are many ways in the online advertising ecosystem that data leaks from publishers to buyers. I know that publishers are aware of this happening, at least abstractly, but do little to stop it. Then these same publishers complain that audience buying is killing the value of quality content. Where do you think that audience is coming from!?!
In a follow-up post, I propose actions that we can take as an industry to address data leakage.
Acknowledgements
Thanks to Tom Shields, Pankaj Lakhotia, Andrew Sweeney, Scott Menzer, Matthew Goldstein, and Ron Lissack for their thoughtful feedback.